5 Manipulación de datos usando tidyverse
Las funciones que hemos estado usando hasta ahora, como read.table y str(), vienen incorporadas en R. Pero existen incontables funciones en R a las que puedes acceder instalando lo que se conoce como paquetes (packages). Antes de usar un paquete por primera vez, primero debes instalarlo y luego debes importarlo en cada sesión de R en la que quieras usarlo.
Hay dos formas de instalar paquetes en R, a través de la consola como ya vimos en la sección ??, y a través de la opción Install en la pestaña Packages de RStudio (opción disponibles para paquetes CRAN solamente):
- Para instalar y cargar el paquete
tidyverseusando RStudio, dirígete a la pestañaPackages->Install-> escribe el nombre del paquete y haz clic en “Install”. Una vez instalado, para importarlo sólo debes identificarlo y seleccionarlo en la lista de paquetes.
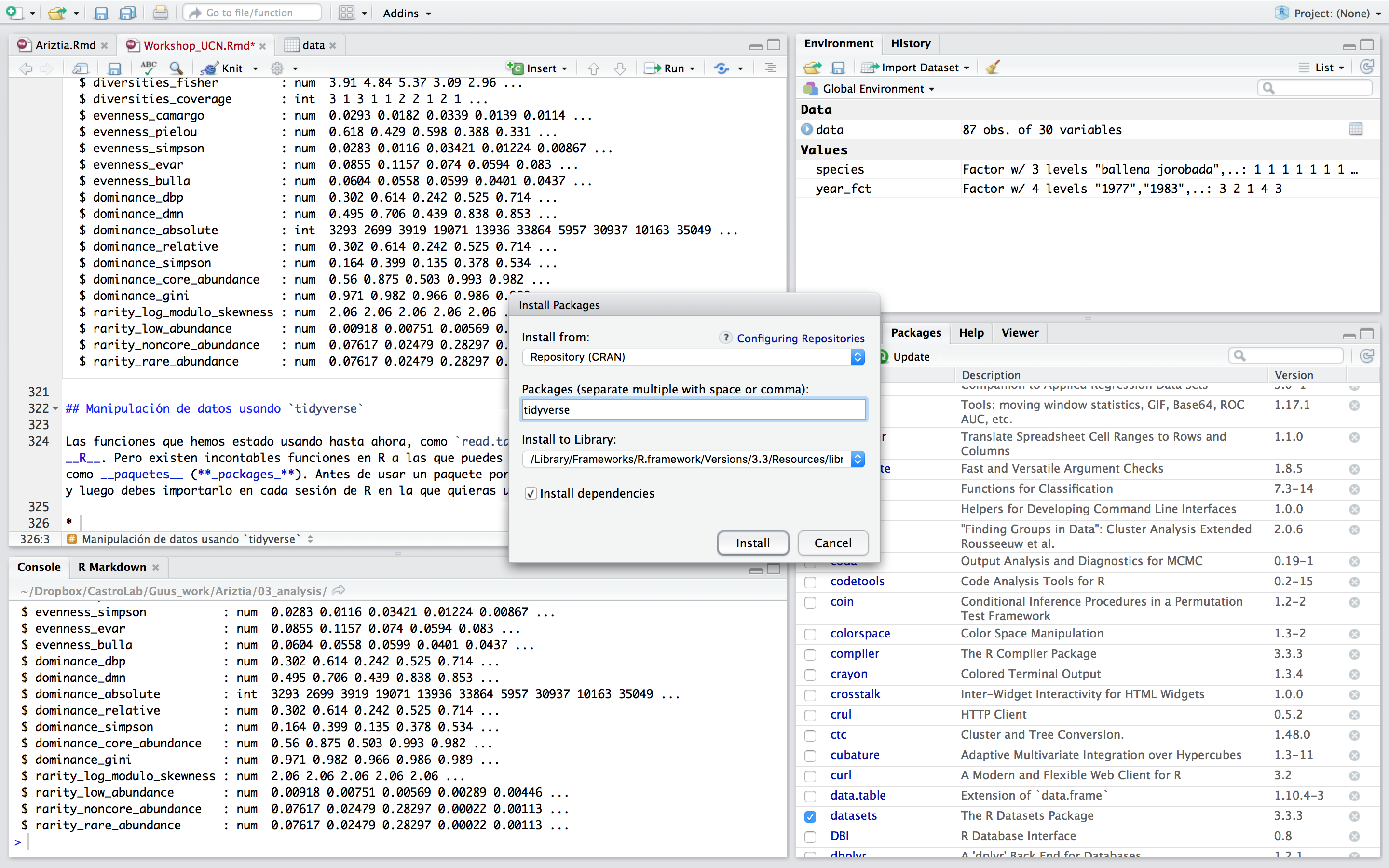 Instalación de paquetes en RStudio.
Instalación de paquetes en RStudio.
tidyverse es un paquete que incluye la instalación varios paquetes útiles para la manipulación y análisis de datos, tales como dplyr, tidyr, ggplot2, etc. Anteriormente practicamos como extraer información de tablas usando [ ], a continuación vamos a utilizar los paquetes dplyr y tidyr para manipular nuestra tabla de datos más fácil, rápido y con más funcionalidades.
- Vamos a leer nuevamente nuestra tabla de datos, ésta vez usando la función
read_csv()del paquetetidyverse:
## Parsed with column specification:
## cols(
## .default = col_double(),
## sample_ID = col_character(),
## geo_loc_name = col_character(),
## species = col_character()
## )## See spec(...) for full column specifications.## tibble [87 × 30] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
## $ sample_ID : chr [1:87] "SRR6442697" "SRR6442698" "SRR6442699" "SRR6442700" ...
## $ geo_loc_name : chr [1:87] "Estrecho de Magallanes" "Estrecho de Magallanes" "Estrecho de Magallanes" "Estrecho de Magallanes" ...
## $ species : chr [1:87] "Megaptera novaeangliae" "Megaptera novaeangliae" "Megaptera novaeangliae" "Megaptera novaeangliae" ...
## $ observed : num [1:87] 31 33 43 29 26 21 37 32 28 30 ...
## $ shannon : num [1:87] 2.12 1.5 2.25 1.31 1.08 ...
## $ richness_0 : num [1:87] 31 33 43 29 26 21 37 32 28 30 ...
## $ richness_20 : num [1:87] 31 33 43 29 26 21 37 32 28 30 ...
## $ richness_50 : num [1:87] 31 33 43 29 26 21 37 32 28 30 ...
## $ richness_80 : num [1:87] 31 33 43 29 26 21 37 32 28 30 ...
## $ diversities_inverse_simpson: num [1:87] 6.11 2.51 7.39 2.64 1.87 ...
## $ diversities_gini_simpson : num [1:87] 0.836 0.601 0.865 0.622 0.466 ...
## $ diversities_shannon : num [1:87] 2.12 1.5 2.25 1.31 1.08 ...
## $ diversities_fisher : num [1:87] 3.91 4.84 5.37 3.09 2.96 ...
## $ diversities_coverage : num [1:87] 3 1 3 1 1 2 2 1 2 1 ...
## $ evenness_camargo : num [1:87] 0.0293 0.0182 0.0339 0.0139 0.0114 ...
## $ evenness_pielou : num [1:87] 0.618 0.429 0.598 0.388 0.331 ...
## $ evenness_simpson : num [1:87] 0.0283 0.0116 0.03421 0.01224 0.00867 ...
## $ evenness_evar : num [1:87] 0.0855 0.1157 0.074 0.0594 0.083 ...
## $ evenness_bulla : num [1:87] 0.0604 0.0558 0.0599 0.0401 0.0437 ...
## $ dominance_dbp : num [1:87] 0.302 0.614 0.242 0.525 0.714 ...
## $ dominance_dmn : num [1:87] 0.495 0.706 0.439 0.838 0.853 ...
## $ dominance_absolute : num [1:87] 3293 2699 3919 19071 13936 ...
## $ dominance_relative : num [1:87] 0.302 0.614 0.242 0.525 0.714 ...
## $ dominance_simpson : num [1:87] 0.164 0.399 0.135 0.378 0.534 ...
## $ dominance_core_abundance : num [1:87] 0.56 0.875 0.503 0.993 0.982 ...
## $ dominance_gini : num [1:87] 0.971 0.982 0.966 0.986 0.989 ...
## $ rarity_log_modulo_skewness : num [1:87] 2.06 2.06 2.06 2.06 2.06 ...
## $ rarity_low_abundance : num [1:87] 0.00918 0.00751 0.00569 0.00289 0.00446 ...
## $ rarity_noncore_abundance : num [1:87] 0.07617 0.02479 0.28297 0.00022 0.00113 ...
## $ rarity_rare_abundance : num [1:87] 0.07617 0.02479 0.28297 0.00022 0.00113 ...
## - attr(*, "spec")=
## .. cols(
## .. sample_ID = col_character(),
## .. geo_loc_name = col_character(),
## .. species = col_character(),
## .. observed = col_double(),
## .. shannon = col_double(),
## .. richness_0 = col_double(),
## .. richness_20 = col_double(),
## .. richness_50 = col_double(),
## .. richness_80 = col_double(),
## .. diversities_inverse_simpson = col_double(),
## .. diversities_gini_simpson = col_double(),
## .. diversities_shannon = col_double(),
## .. diversities_fisher = col_double(),
## .. diversities_coverage = col_double(),
## .. evenness_camargo = col_double(),
## .. evenness_pielou = col_double(),
## .. evenness_simpson = col_double(),
## .. evenness_evar = col_double(),
## .. evenness_bulla = col_double(),
## .. dominance_dbp = col_double(),
## .. dominance_dmn = col_double(),
## .. dominance_absolute = col_double(),
## .. dominance_relative = col_double(),
## .. dominance_simpson = col_double(),
## .. dominance_core_abundance = col_double(),
## .. dominance_gini = col_double(),
## .. rarity_log_modulo_skewness = col_double(),
## .. rarity_low_abundance = col_double(),
## .. rarity_noncore_abundance = col_double(),
## .. rarity_rare_abundance = col_double()
## .. )Como podrás notar, la función read_csv() hace algunos cambios al cargar la tabla con respecto a lo que revisamos anteriormente usando read.table(). Las diferencias son:
- Al leer la tabla, muestra un resumen del tipo de dato de cada columna, y sólo muestra las primeras filas y tantas columnas como se puedan visualizar en la pantalla.
- Las columnas de clase
character(caracteres) no son convertidas en factores.
A continuación vamos a aprender algunas de las funciones más comunes de dplyr:
select(): extraer columnas.filter(): extraer filas según condiciones.mutate(): crear nuevas columnas usando la información de otras columnas.group_by()ysummarize(): cálcula estadísticas en datos agrupados.arrange(): ordena resultados.count(): conteo de datos.
5.1 Seleccionar columnas y filtrar filas
- Para seleccionar columnas de una tabla de datos o data frame, vamos a usar la función
select(). Luego, para seleccionar filas de acuerdo a cierto criterio (filtrar), vamos a usar la funciónfilter().
dplyr::select(data, sample_ID, geo_loc_name, species, observed) # los argumentos son, primero el objeto que contiene el data frame, y luego los títulos de las columnas a extraer## # A tibble: 87 x 4
## sample_ID geo_loc_name species observed
## <chr> <chr> <chr> <dbl>
## 1 SRR6442697 Estrecho de Magallanes Megaptera novaeangliae 31
## 2 SRR6442698 Estrecho de Magallanes Megaptera novaeangliae 33
## 3 SRR6442699 Estrecho de Magallanes Megaptera novaeangliae 43
## 4 SRR6442700 Estrecho de Magallanes Megaptera novaeangliae 29
## 5 SRR6442701 Estrecho de Magallanes Megaptera novaeangliae 26
## 6 SRR6442702 Estrecho de Magallanes Megaptera novaeangliae 21
## 7 SRR6442703 Estrecho de Magallanes Megaptera novaeangliae 37
## 8 SRR6442704 Estrecho de Magallanes Megaptera novaeangliae 32
## 9 SRR6442705 Estrecho de Magallanes Megaptera novaeangliae 28
## 10 SRR6442706 Estrecho de Magallanes Megaptera novaeangliae 30
## # … with 77 more rowsdplyr::filter(data, geo_loc_name == "Chiloe") # los argumentos son, primero el objeto que contiene el data frame, y luego la columna con el criterio de filtro## # A tibble: 28 x 30
## sample_ID geo_loc_name species observed shannon richness_0 richness_20
## <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 SRR64427… Chiloe Megapt… 63 1.28 63 63
## 2 SRR64427… Chiloe Megapt… 14 0.732 14 14
## 3 SRR64427… Chiloe Balaen… 18 1.41 18 18
## 4 SRR64427… Chiloe Balaen… 19 1.68 19 19
## 5 SRR64427… Chiloe Balaen… 36 2.31 36 36
## 6 SRR64427… Chiloe Balaen… 63 1.31 63 63
## 7 SRR64427… Chiloe Balaen… 29 1.73 29 29
## 8 SRR64427… Chiloe Balaen… 38 1.65 38 38
## 9 SRR64427… Chiloe Balaen… 81 2.05 81 81
## 10 SRR64427… Chiloe Balaen… 78 0.725 78 78
## # … with 18 more rows, and 23 more variables: richness_50 <dbl>,
## # richness_80 <dbl>, diversities_inverse_simpson <dbl>,
## # diversities_gini_simpson <dbl>, diversities_shannon <dbl>,
## # diversities_fisher <dbl>, diversities_coverage <dbl>,
## # evenness_camargo <dbl>, evenness_pielou <dbl>, evenness_simpson <dbl>,
## # evenness_evar <dbl>, evenness_bulla <dbl>, dominance_dbp <dbl>,
## # dominance_dmn <dbl>, dominance_absolute <dbl>, dominance_relative <dbl>,
## # dominance_simpson <dbl>, dominance_core_abundance <dbl>,
## # dominance_gini <dbl>, rarity_log_modulo_skewness <dbl>,
## # rarity_low_abundance <dbl>, rarity_noncore_abundance <dbl>,
## # rarity_rare_abundance <dbl>¿Quieres seleccionar y filtrar al mismo tiempo? Claro! Hay formas de hacer varias operaciones consecutivas en una misma instrucción, de esta manera evitamos tener que guardar objetos “intermedios” innecesariamente.
5.2 Funciones anidadas y pipes
- Vamos a anidar funciones (i.e. una función dentro de otra):
## [1] 87## [1] 30data_div <- dplyr::select(dplyr::filter(data, shannon > 1.5), sample_ID, geo_loc_name, species, observed, shannon)
head(data_div)## # A tibble: 6 x 5
## sample_ID geo_loc_name species observed shannon
## <chr> <chr> <chr> <dbl> <dbl>
## 1 SRR6442697 Estrecho de Magallanes Megaptera novaeangliae 31 2.12
## 2 SRR6442699 Estrecho de Magallanes Megaptera novaeangliae 43 2.25
## 3 SRR6442703 Estrecho de Magallanes Megaptera novaeangliae 37 1.86
## 4 SRR6442708 Estrecho de Magallanes Megaptera novaeangliae 27 1.91
## 5 SRR6442709 Estrecho de Magallanes Megaptera novaeangliae 36 1.88
## 6 SRR6442712 Estrecho de Magallanes Megaptera novaeangliae 36 1.94## [1] 39## [1] 5Es importante recordar que R lee la línea de comando desde dentro hacia fuera. En éste caso, primero se hizo el filtro y luego la selección.
- Usar funciones anidadas puede ser engorroso cuando quieres hacer muchas operaciones consecutivas, en cuyo caso es convenientes usar pipes. Pipes te permiten usar varias funciones consecutivas, de forma que el output de una función será en input de la siguiente. Los pipes en R lucen así:
%>%.
data %>%
dplyr::filter(shannon > 1.5) %>%
dplyr::select(sample_ID, geo_loc_name, species, observed, shannon)## # A tibble: 39 x 5
## sample_ID geo_loc_name species observed shannon
## <chr> <chr> <chr> <dbl> <dbl>
## 1 SRR6442697 Estrecho de Magallanes Megaptera novaeangliae 31 2.12
## 2 SRR6442699 Estrecho de Magallanes Megaptera novaeangliae 43 2.25
## 3 SRR6442703 Estrecho de Magallanes Megaptera novaeangliae 37 1.86
## 4 SRR6442708 Estrecho de Magallanes Megaptera novaeangliae 27 1.91
## 5 SRR6442709 Estrecho de Magallanes Megaptera novaeangliae 36 1.88
## 6 SRR6442712 Estrecho de Magallanes Megaptera novaeangliae 36 1.94
## 7 SRR6442714 Estrecho de Magallanes Megaptera novaeangliae 26 1.81
## 8 SRR6442715 Estrecho de Magallanes Megaptera novaeangliae 35 1.61
## 9 SRR6442722 Chiloe Balaenoptera musculus 19 1.68
## 10 SRR6442723 Chiloe Balaenoptera musculus 36 2.31
## # … with 29 more rowsComo %>% pasa el objeto de su izquierda como el primer argumento de la función a su derecha, no necesitamos especificar el data frame como el primer argumento de las funciones filter() y select().
5.3 Mutate: crear nuevas columnas desde información existente en otras columnas
En algunas ocasiones necesitamos generar nueva información a partir de la existente, por ejemplo, para hacer conversiones o cálculos matemáticos.
data <- data %>%
mutate(log10_dom_abs = log10(dominance_absolute))
# Dale un vistazo a la tabla (View(data)), la última columna es la nueva "log10_dom_abs", también notarás que, en la pestaña "Environment" de RStudio, ahora el objeto "data" tiene "31 variables".
# Si deseas tener una vista previa de como quedará tu "data" antes de guardar cualquier cambio, puedes usar pipe para agregar la función head() al final
data %>%
mutate(log10_dom_abs = log10(dominance_absolute)) %>%
head()## # A tibble: 6 x 31
## sample_ID geo_loc_name species observed shannon richness_0 richness_20
## <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 SRR64426… Estrecho de… Megapt… 31 2.12 31 31
## 2 SRR64426… Estrecho de… Megapt… 33 1.50 33 33
## 3 SRR64426… Estrecho de… Megapt… 43 2.25 43 43
## 4 SRR64427… Estrecho de… Megapt… 29 1.31 29 29
## 5 SRR64427… Estrecho de… Megapt… 26 1.08 26 26
## 6 SRR64427… Estrecho de… Megapt… 21 1.13 21 21
## # … with 24 more variables: richness_50 <dbl>, richness_80 <dbl>,
## # diversities_inverse_simpson <dbl>, diversities_gini_simpson <dbl>,
## # diversities_shannon <dbl>, diversities_fisher <dbl>,
## # diversities_coverage <dbl>, evenness_camargo <dbl>, evenness_pielou <dbl>,
## # evenness_simpson <dbl>, evenness_evar <dbl>, evenness_bulla <dbl>,
## # dominance_dbp <dbl>, dominance_dmn <dbl>, dominance_absolute <dbl>,
## # dominance_relative <dbl>, dominance_simpson <dbl>,
## # dominance_core_abundance <dbl>, dominance_gini <dbl>,
## # rarity_log_modulo_skewness <dbl>, rarity_low_abundance <dbl>,
## # rarity_noncore_abundance <dbl>, rarity_rare_abundance <dbl>,
## # log10_dom_abs <dbl>5.4 Dividir -> aplicar -> combinar
Varias operaciones de análisis de datos se pueden realizar, primero dividiendo los datos en grupos, segundo aplicando análisis a cada grupo, y tercero combinando los resultados. Hacemos esto usando las funciones group_by() y summarize() juntas. group_by() toma como argumento los nombres de la columna que contiene valores categóricos, a partir de las cuales queremos hacer algún cálculo. summarize() colapsa cada grupo en una única fila.
- Vamos a calcular el promedio y desviación estándar (
mean();sd()) del número de taxas observadas (columna “observed”) por zona (columna “geo_loc_name”) y especie (columna “species”) de ballena:
data %>%
group_by(geo_loc_name, species) %>% # puedes agrupar por una o múltiples columnas
summarize(mean_observed = mean(observed), # una vez que los datos están agrupados, también puedes aplicar múltiples análisis al mismo tiempo y en múltiples variables
sd_observed = sd(observed),
mean_shannon = mean(shannon),
sd_shannon = sd(shannon))## `summarise()` regrouping output by 'geo_loc_name' (override with `.groups` argument)## # A tibble: 5 x 6
## # Groups: geo_loc_name [3]
## geo_loc_name species mean_observed sd_observed mean_shannon sd_shannon
## <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Chiloe Balaenopt… 55.0 19.9 1.57 0.568
## 2 Chiloe Megaptera… 38.5 34.6 1.00 0.385
## 3 Estrecho de Maga… Megaptera… 33.5 7.60 1.42 0.457
## 4 Reserva Nacional… Balaenopt… 33.9 22.3 1.34 0.717
## 5 Reserva Nacional… Megaptera… 43.3 23.6 1.52 0.564- Si lo necesitas, también puedes agregar un filtro antes de agrupar los datos y hacer estadística de los grupos. Por ejemplo, supongamos que decidimos no considerar aquellas muestras con menos de 20 taxas (
observed< 20):
data %>%
dplyr::filter(observed > 20) %>%
group_by(geo_loc_name, species) %>%
summarize(mean_observed_min20 = mean(observed)) %>%
print() # para ver el resultado (output) en la consola## `summarise()` regrouping output by 'geo_loc_name' (override with `.groups` argument)## # A tibble: 5 x 3
## # Groups: geo_loc_name [3]
## geo_loc_name species mean_observed_min…
## <chr> <chr> <dbl>
## 1 Chiloe Balaenoptera musculus 59.7
## 2 Chiloe Megaptera novaeangliae 63
## 3 Estrecho de Magallanes Megaptera novaeangliae 33.5
## 4 Reserva Nacional Pinguino de Humbol… Balaenoptera physalus 46.8
## 5 Reserva Nacional Pinguino de Humbol… Megaptera novaeangliae 49.2- Muchas veces es útil re-organizar los datos para una más eficiente interpretación de los resultados. Por ejemplo, si queremos ordenar los resultados por número promedio de taxa observado por grupo (“mean_observed”) en orden decreciente:
data %>%
group_by(geo_loc_name, species) %>%
summarize(mean_observed = mean(observed),
sd_observed = sd(observed),
mean_shannon = mean(shannon),
sd_shannon = sd(shannon)) %>%
arrange(desc(mean_observed)) # la función arrange(), por defecto, ordena los datos en orden creciente, usamos la función desc() para ordenar en orden decreciente## `summarise()` regrouping output by 'geo_loc_name' (override with `.groups` argument)## # A tibble: 5 x 6
## # Groups: geo_loc_name [3]
## geo_loc_name species mean_observed sd_observed mean_shannon sd_shannon
## <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Chiloe Balaenopt… 55.0 19.9 1.57 0.568
## 2 Reserva Nacional… Megaptera… 43.3 23.6 1.52 0.564
## 3 Chiloe Megaptera… 38.5 34.6 1.00 0.385
## 4 Reserva Nacional… Balaenopt… 33.9 22.3 1.34 0.717
## 5 Estrecho de Maga… Megaptera… 33.5 7.60 1.42 0.4575.5 Contar
La función count() nos permite conocer el número de observaciones por cada variable, o combinación de ellas, en tus datos.
5.6 Remodelar tablas usando spread() y gather()
Con el objetivo de explorar las relaciones entre ciertas variables de interés en nuestros datos, podemos remodelar la tabla de datos de acuerdo a éstas variables.
Supongamos que nos interesa explorar la relación entre la diversidad del microbioma de la piel (“shannon”) de las especies de ballena (“species”) y su locación geográfica.
- Primero, necesitamos usar
group_by()ysummarize(), para agrupar nuestras variables de interés y crear una nueva columna con los valores de índice de Shannon promedio para cada grupo. Después, usamos la funciónspread()para transformardatade modo que: cada especie ahora sea una columna, cada locación geográfica ahora sea una fila, y los valores de Shannon estén en cada celda según corresponda.
data_spread <- data %>%
group_by(geo_loc_name, species) %>%
summarize(mean_shannon = mean(shannon)) %>%
spread(key = species, value = mean_shannon, fill = NA)## `summarise()` regrouping output by 'geo_loc_name' (override with `.groups` argument)## # A tibble: 3 x 4
## # Groups: geo_loc_name [3]
## geo_loc_name `Balaenoptera musc… `Balaenoptera phy… `Megaptera novaea…
## <chr> <dbl> <dbl> <dbl>
## 1 Chiloe 1.57 NA 1.00
## 2 Estrecho de Magalla… NA NA 1.42
## 3 Reserva Nacional Pi… NA 1.34 1.52# Como el número de taxa observada varía por cada muestra, tenemos como resultado varias celdas "NA" ("missing data"). Para éstos casos, la función spread() viene con el argumento "fill".Ahora vamos a suponer la situación contraria. Inicialmente, tenemos una tabla de datos como data_spread, en la que los nombres de las especies (“species”) son columnas, pero en vez de ello, queremos que las especies sean valores de la variable “species” (columna: “species”).
- Para lograrlo, necesitamos reunir los nombres de las columnas (especies) y convertirlos en un set de variables:
data_gather <- data_spread %>%
gather(key = species, value = mean_shannon, -geo_loc_name) %>%
dplyr::filter(!is.na(mean_shannon))
head(data_gather)## # A tibble: 5 x 3
## # Groups: geo_loc_name [3]
## geo_loc_name species mean_shannon
## <chr> <chr> <dbl>
## 1 Chiloe Balaenoptera musculus 1.57
## 2 Reserva Nacional Pinguino de Humboldt Balaenoptera physalus 1.34
## 3 Chiloe Megaptera novaeangliae 1.00
## 4 Estrecho de Magallanes Megaptera novaeangliae 1.42
## 5 Reserva Nacional Pinguino de Humboldt Megaptera novaeangliae 1.52La función is.na() determina si un dato es NA (Not Available). El símbolo ! niega el el resultado. Por lo tanto, al usar !is.na(mean_shannon) estamos pidiendo por valor que no es NA en la columna mean_shannon.
5.7 Exportar datos
El trabajo hecho en una sesión de R (e.g., análisis, nuevas tablas, etc.) sólo existe en la memoria de R mientras la sesión esté abierta. Necesitas exportar los nuevos datos creados para archivarlos en tu computadora. Entonces, así como existe la función read_csv() para leer archivos CSV (comma-separated values) en R, hay una función para generar archivos CSV a partir de tablas de datos en contenidas como objetos en la memoria de R.
- Por ejemplo, para exportar el data frame que creamos recién usando la función
gather()yfilter():